
티스토리 뷰
안녕하세요. 은행 IT 운영부 이지성과장입니다.
오늘은 텍스트 형태의 데이터를 자동으로 가져오는 웹크롤링 기술에 대해서 알아보도록 하겠습니다.
잘 아시겠지만, 웹 상의 모든 페이지는 HTML등의 웹문서로 되어있습니다.

이러한 문서에는 HTML태그 및 데이터가 함께 들어가 있기 때문에 이러한 데이터를 찾아 필요한 데이터를 수집 할 수 있게 되는겁니다.
이것을 잘 활용하면, 특정 영화에 대한 리뷰, 특정 상품에 대한 상품평 등 대량의 텍스트 데이터를 자동으로 수집할 수 있게 되고, 이것을 잘 분석 후 여러가지 상황에서 의사결정에 사용하는 밑거름이 되겠지요!
"다잇소" 홈페이지의 예시로 살펴보면,
홈페이지에 접속하셔서 우클릭-소스보기 하시면 html 소스를 보실 수 있습니다.
그리고 여러가지 html 태그와 텍스트 정보들이 보이실 겁니다. (빨간색 부분 참고)
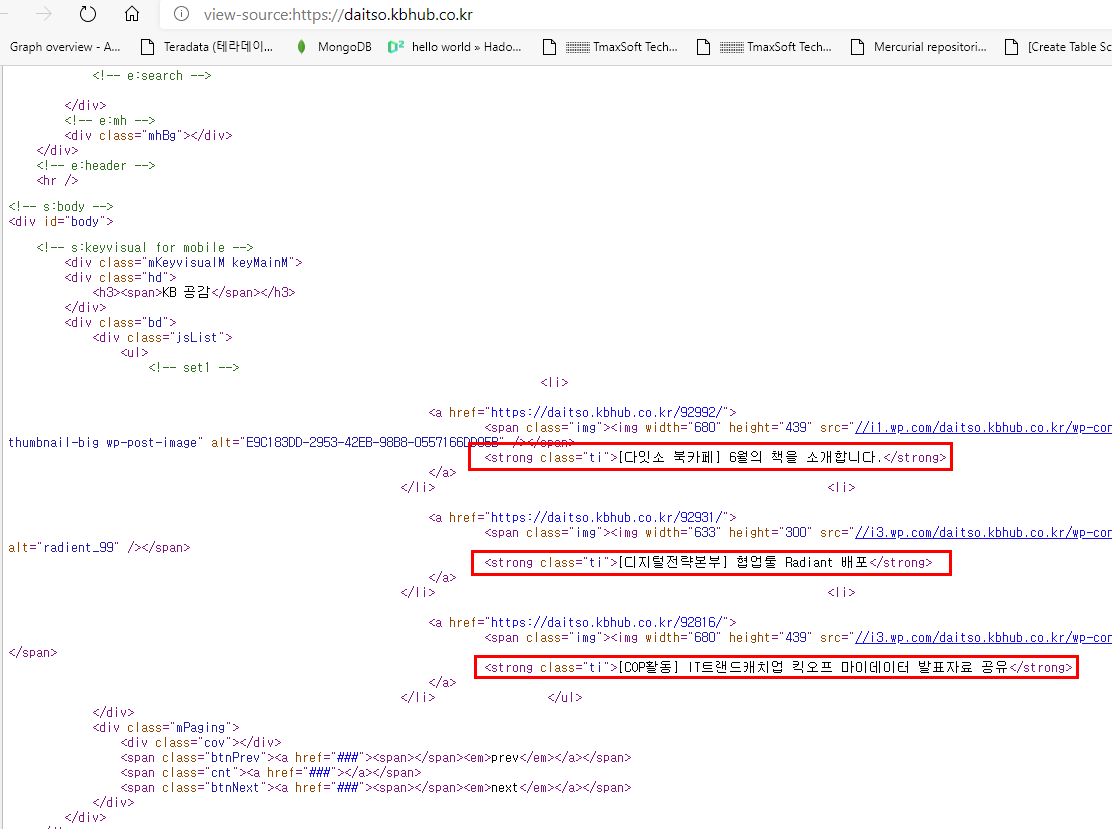
위와 같이 HTML 페이지의 특정 부분을 긁어올 수 있습니다.
그런데 selenium 이라는 오픈 API와 크롤링 기술이 결합을 하면 막강한 나만의 크롤링 툴을 만들 수 있습니다.
selenium은 사실 "자동화 테스팅 도구" 입니다. 사용자가 어떤 로직을 생성해두면 스스로 사이트 곳곳을 돌아다닐 수 있습니다.
그리고 selenium의 강점은, 사용자 id/pw를 입력하고, 로그인 이후의 웹 페이지들의 크롤링도 가능하다는 것입니다.
selenium이 동작을 설정하는 설정파일에 아래와 같이 id와 password를 입력하면, 웹페이지 접속 -> 로그인 -> 페이저 이동 -> html 소스 수집을 자동으로 할 수 있는 것입니다.
비슷한 기술로 "스크래핑" 이란 기술이 있는데요.
뱅크 샐러드나 토스 등에서 본인의 카드 사용내역, 보험 가입내역 등 금융정보를 가져올 때 사용되는 기술입니다.

자세한 내용은 아래 링크를 참고하시면 좋을 것 같습니다!
[LINK] : http://blog.naver.com/wineservice/221093519282
다음 포스팅에서는 다들 아시는 사이버강좌 사이트인 "KBWITH" 사이트를 기준으로 selenium을 이용해 한번 크롤링을 해보도록 하겠습니다. 긁어올 내용으로는 KBWITH에 있는 강좌 리스트와 그 내용에 대해서 긁어보도록 하겠습니다. ^^;
장마 이후 더위가 올것으로 예상되는데요...무더위를 극복하는 7월의 시작 되시기 바랍니다.
'python programming' 카테고리의 다른 글
| [pandas] csv 파일 로드 및 encode / decode (0) | 2022.07.27 |
|---|---|
| 내용 기반 (contents based) 추천 시스템 구축해보기 (0) | 2020.05.04 |
| 워드임베딩(word-embedding) word2vec 알아보기 (0) | 2020.03.04 |
- Total
- Today
- Yesterday
- s3
- 131회정보관리기술사
- 정보관리기술사독학
- 밀키트요리
- 정보관리기술사
- r
- iso12207
- IIS
- gpt3.5
- hackerrank
- 기술사학원
- 12207
- 추천시스템
- 머신러닝
- 로블록스
- 밀키트
- 인조기프
- ISO 12207
- 콘도챗봇
- 기술사
- pytorch
- lambda
- AWS
- 챗봇
- 추천도서
- 정보관리기술사합격
- 정보관리
- FLASK
- 자기계발
- wfastcgi
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |