
티스토리 뷰
안녕하세요. 은행 IT 운영부 이지성과장입니다.
오늘은 자연어 처리 기법에서 (NPL라고도 합니다) "워드 임베딩" 기법 중 가장 유명한 word2vec에 대해서 알아보겠습니다.
먼저 "임베딩"이란 단어에 초점을 좀 맞추어볼 필요가 있는데요. "끼워넣다"라는 의미의 임베딩은, 단어나 문장을 각각 벡터로 변환해 벡터 공간에 끼워넣는 겁니다. 즉, 단어나 문장의 벡터화를 워드 임베딩이라고 하는데, 벡터화를 왜 하냐구요?
단어를 벡터화 하면 단어자체를 수학적으로 표현하여 연산도 가능하다고 합니다.
예를들어 한국 + 서울 = 일본 + ? 했을 때, 컴퓨터가 ? = 도쿄 라고 알아 듣는다는 겁니다.
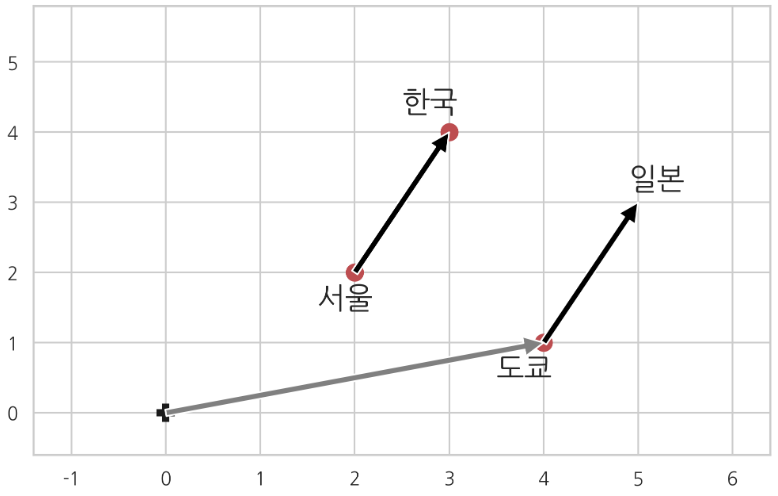
워드 임베딩의 기법에는 LSA, Word2Vec, FastText, Glove 등의 기법이 있는데, 이번 시간에는 가장 유명한 Word2Vec에 대해서 알아보도록 하겠습니다.
Word2Vec은 2013년 구글에서 발표한 단어 임베딩 모델로, 2가지 방식이 제안되었습니다.
Skip-gram 모델과 CBOW 두가지 인데요. CBOW는 주변에 있는 문맥 단들을 가지고, 타깃단어를 맞추는 과정에서 학습되고, Skip-gram은 타깃단어를 가지고 주변 문맥 잔어가 무엇일 지 예측하는 과정에서 학습이 된다고 합니다.

예를 들어 "나는 매일 파이썬을 공부한다"라는 문장에서 '파이썬'를 타깃 단어로 보면, 여기에 윈도(window)를 좌우 2단어라고 하면 주변 단어는 "는", "매일", "을", "공부"가 될 것입니다. CBOW는 주변단어의 임베딩을 더해서 대상단어를 예측하고, Skip-Gram은 대상 단어의 임베딩으로 주변단어를 예측합니다. Skip-gram이 같은 데이터로 많은 학습을 할 수 있어 성능이 더 좋은 것으로 알려져 있습니다.
또한 word2vec의 장점은 동음이의어를 분리할 수 있다는 겁니다. 쉽게 말씀드리면, 먹는 "사과" 와 sorry의 "사과"의 의미상으로 다른 벡터값을 가지려면, 주변단어를 보면 된다는 논리입니다.
<1> 먹는 사과가 쓰인 문장의 예
나는 사과는 먹었다.
맛잇는 사과를 먹고
<2> sorry 의미로 사과가 쓰인 문장의 예
어제 사과를 했어요.
미안하다고 사과하세요.
"사과"를 기준으로 주변 단어들을 보면 차이가 있기 때문에, 이를 학습하면 같은 사과라도 다른 벡터값을 갖게 분리 할 수 있다는 것이지요.
지금부터 word2vec을 코딩을 통해서 정리해 보도록 하겠습니다.
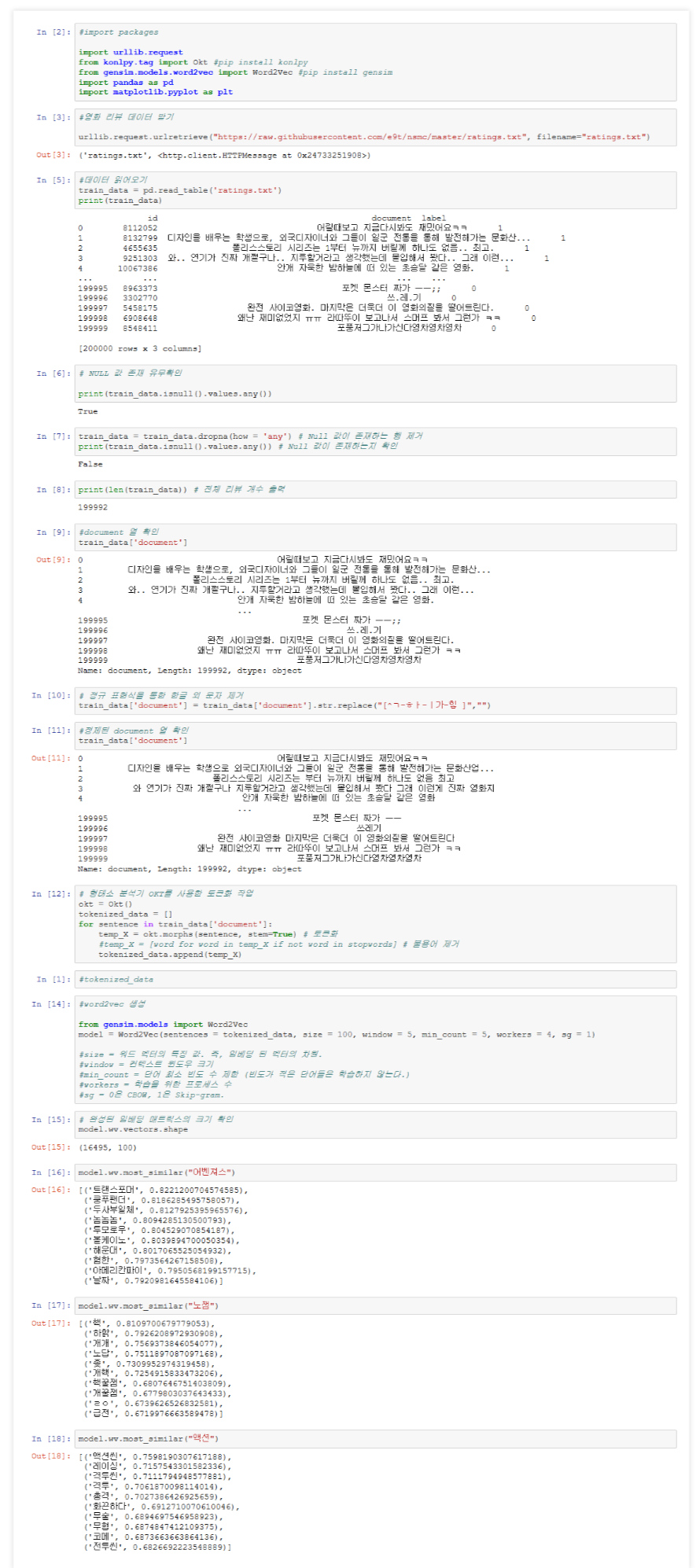
1) 아래 사진에서 보시면, word2vec은 gensim 라이브러리를 사용합니다.
(from gensim.models.word2vec import Word2Vec) 하셔서 라이브러리를 호출하셔야 합니다.
2) 영화 리뷰 데이터는 깃허브에 누군가가 올려둔 리뷰 데이터(ratings.txt)를 받아서 사용하였습니다.
3) txt 파일을 읽어 올 때는 pandas 라이브러리를 사용하였습니다 (import pandas as pd)
4) pd.read_table(파일명) 하시면, 해당 파일을 읽어 옵니다.
5) 특수문자를 제거하고, OKT 형태소 분석기를 사용하여, 형태소를 분리합니다.
6) 형태소 분석기 목적은(명사 , 형용사, 부사 등등.. ) 품사 태깅을 할 수 있는 형태로 분리함 입니다. (토크나이징이라고도 합니다)
7) word2vec model을 생성하는 부분은 아래와 같습니다.
#word2vec 생성
from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, size = 100, window = 5, min_count = 5, workers = 4, sg = 1)
#size = 워드 벡터의 특징 값. 즉, 임베딩 된 벡터의 차원.
#window = 컨텍스트 윈도우 크기
#min_count = 단어 최소 빈도 수 제한 (빈도가 적은 단어들은 학습하지 않는다.)
#workers = 학습을 위한 프로세스 수
#sg = 0은 CBOW, 1은 Skip-gram.
8) model을 생성하여 재밌는 결과를 보실 수 있습니다.
<1> 어벤져스와 가장 가까운 단어
model.wv.most_similar("어벤져스")
Out[16]:
[('트랜스포머', 0.8221200704574585), ('쿵푸팬더', 0.8186285495758057), ('두사부일체', 0.8127925395965576), ('놈놈놈', 0.8094285130500793), ('투모로우', 0.804529070854187), ('볼케이노', 0.8039894700050354), ('해운대', 0.8017065525054932), ('혐한', 0.7973564267158508), ('아메리칸파이', 0.7950568199157715), ('날짜', 0.7920981645584106)]
<2> 액션 과 가장 가까운 단어
model.wv.most_similar("액션")
Out[18]:
[('액션씬', 0.7598190307617188), ('레이싱', 0.7157543301582336), ('격투씬', 0.7111794948577881), ('격투', 0.7061870098114014), ('총격', 0.7027386426925659), ('화끈하다', 0.6912710070610046), ('무술', 0.6894697546958923), ('무협', 0.6874847412109375), ('코메', 0.6873663663864136), ('전투씬', 0.6826692223548889)
이렇게 word2vec은 스스로 학습하여, 문장, 단어 단위로 벡터화 하여, 여러곳에 활용될 수 있습니다.
사용자 리뷰에서 특정사용자의 성향을 뽑아낼 수도 있고,
여러 신문기사에서 주제를 도출할 때도 사용될 수 있습니다.
여러 신문기사 중에서 주제를 도출하여 사용자에게 맞춤 형식의 기사를 제공하는 추천 시스템에도 활용될 수 있겠네요.
정말 매력적이지 않나요??
이 모든 과정은 제 개인 깃허브에 업로드 해두었습니다.
따듯한 4월 봄날의 시작 되시길 바랍니다.
깃허브링크 : https://github.com/jasonlee8318/Python/blob/master/cinema_review_word2vec.py
'python programming' 카테고리의 다른 글
| [pandas] csv 파일 로드 및 encode / decode (0) | 2022.07.27 |
|---|---|
| 웹크로링, 스프래핑 기술에 대하여 (0) | 2020.05.13 |
| 내용 기반 (contents based) 추천 시스템 구축해보기 (0) | 2020.05.04 |
- Total
- Today
- Yesterday
- 기술사학원
- 추천시스템
- 로블록스
- 추천도서
- FLASK
- ISO 12207
- 밀키트요리
- gpt3.5
- 머신러닝
- 챗봇
- 정보관리기술사합격
- 정보관리기술사독학
- s3
- 인조기프
- pytorch
- 정보관리기술사
- 콘도챗봇
- iso12207
- AWS
- 131회정보관리기술사
- hackerrank
- 정보관리
- 기술사
- 자기계발
- lambda
- 12207
- wfastcgi
- r
- IIS
- 밀키트
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |