
티스토리 뷰
안녕하세요. 은행IT운영부 이지성과장입니다.
오늘은 자연어 처리 기법 중 하나인 TF-IDF, 단어-역문서 빈도라고도 하는데요.
바로 이 TF-IDF 에 대해서 알아보도록 하겠습니다.

TF-IDF의 약자와 설명은 아래와 같습니다.
1. TF : Term Frequencey , 단어빈도
- 특정 문서에서 나타나는 특정 단어의 총 횟수입니다.
2. IDF : Inverse Document Frequency , 역문서 빈도
- TF와 반대되는 개념으로 특정 단어가 나타나는 문서의 수 입니다.
이렇게 설명만 보면 이해가 잘 안되시죠?? ㅜㅜ
그래서 더 알기 쉽게 설명 들어갑니다.
아래와 같이 4개의 문서가 있다고 가정해 보겠습니다.
문서1: i love a dog.
문서2: i love a cat not a dog.
문서3: i love a baseball.
문서4: baseball is a most popular in USA.
4개의 문서에서 보시면 "a"라는 단어가 각 문서당 1개씩 총 4번 쓰인 것을 알 수 있습니다.
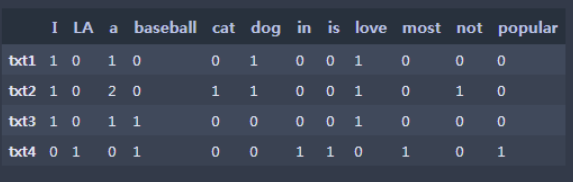
그렇다면 "a"라는 단어가 각 문서의 내용을 결정 지을 수 있는 대표 단어라고 할 수 있을 까요?
아마 그렇지 않을 겁니다. 각 문서에서 많이 쓰이는 단어보다는 , 즉 여기저기서 많이 쓰이는 단어 자체는
의미가 없다고 보는 것이 나을 것입니다.
이럴 때, 특정 단어에서만 사용되는 그런 단어들을 선별하여 가중치를 주는 것이 IDF 입니다.
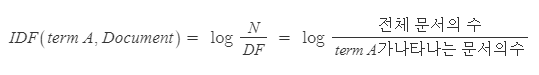
TF-IDF는 TF의 값과 IDF 의 값의 곱 (TF * IDF) 로 계산이 되는데요. TF의 값이 커지고,
IDF 값이 커져서 두 값의 곱이 큰 값을 갖는다면, 이 단어는 매우 의미있는 단어겠죠??!
다시 더 쉽게 말씀드리면 TF 값이 크다 --> 문서 내에서 많이 사용되는 단어이다
IDF 값이 크다 --> 하지만 여러 문서에서 나타나는 단어는 아니다.
결론 TF*IDF 값이 크다면 --> 많이 사용되는 단어이면서 여러 문서에서 공통으로 나타나는 단어가 아닌 의미있는 단어이다.
이렇게 생각하시면 될 것 같습니다.
그렇다면 TF-IDF는 어떤 상황에서 쓰이냐구요?
기사,논문,리뷰 등을 요약할 때 주로 쓰입니다.
기사에서 주로 사용된 단어, 의미있는 단어들을 찾아주어서 주제등을 유추할 수 있죠.
그리고 유추된 단어를 통해 서로 비슷한 기사들을 그룹핑 할수 도 있습니다.
조금 더 이론적인 부분은 아래 링크를 참고하시기 바라겠습니다!
링크 : https://blog.naver.com/pasudo123/221064463377
링크2: https://blog.naver.com/myincizor/221823805086
어느덧 8월입니다. 무더위 속에서 그리고 코로나 위험 속에서 각 근무지에서 열심히 근무하시는
여러분들을 응원하며, 건강한 8월 되시길 바라겠습니다.

'NLP' 카테고리의 다른 글
| 나이브베이즈 분류를 이용한 스팸 필터링 알아보기 (0) | 2020.11.23 |
|---|---|
| 형태소 분석기 알아보기 (0) | 2020.10.08 |
| LDA (Latent Dirichlet Allocation) 알아보기 (0) | 2020.05.13 |
| [데이터 시각화] word cloud (0) | 2020.02.28 |
| 나이브 베이즈를 이용한 스팸 필터링 (0) | 2020.02.26 |
- Total
- Today
- Yesterday
- 정보관리기술사합격
- 정보관리
- 정보관리기술사독학
- IIS
- ISO 12207
- s3
- wfastcgi
- 추천시스템
- 12207
- lambda
- 밀키트
- 기술사학원
- iso12207
- FLASK
- 정보관리기술사
- 로블록스
- 챗봇
- AWS
- 콘도챗봇
- 인조기프
- 131회정보관리기술사
- 기술사
- gpt3.5
- pytorch
- 머신러닝
- r
- 자기계발
- 추천도서
- hackerrank
- 밀키트요리
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |